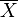en una importante empresa de mercado inicio un estudio sobre habitos de salud en un sector de estrato 3 de una sociedad capital. Para hacer dicho estudio contrato a varios encuestadores que, en promedio, aplicaron 30 encuestas al dia, con una desviacion estándar de 5.
utiliza el teorema de Chebychev para determinar el porcentaje de encuestas aplicadas dentro de cada uno de los siguientes intervalos.
- 20 a 40
- 15 a 45
- 22 a 38
- 18 a 42
los resultados de una encuesta nacional aplicada a 1.154 estudiantes mostraron que, en promedio, los adultos duermen 6,9 horas por dia durante una semana de trabajo. Si la desviación estándar en este estudio fue 1,2 horas
- calcula el porcentaje de individuos que duerme entre 4,5 y 9,3 horas por dia.